Web scraping is a programmed strategy to get enormous amounts of information from websites. Most of this information is unstructured information in an HTML format which is at that point changed over into organized information in a spreadsheet or a database so that it can be used in different applications. There are many distinctive ways to perform web scraping to get information from websites. These incorporate using online administrations, specific API’s or indeed making your code for web scraping from scratch. Many websites allow you to get to their information in an organized format. This is often the most excellent choice, but there are other sites that do not allow users to get massive amounts of information in an organized format or they are not that innovatively progressed. In that circumstance, it is best to use web scraping to scrape the site for information.
Python is the most popular language in the current days used for web scraping. Python has various libraries available for web scraping. At the same time, we can use .NET also for web scraping. Some third-party libraries allow us to scrape data from various sites.
HtmlAgilityPack is a common library used in .NET for web scraping. They have recently added the .NET Core version also for web scraping.
We will use our C# Corner site itself for web scraping. C# Corner gives RSS feeds for each author. We can get information like articles / blogs link, published date, title, feed type, author name from these RSS feeds. We will use HtmlAgilityPack library to crawl the data for each article / blog post and get required information. We will add this information to an SQL database. So that we can use this data for future usage like article statistics. We will use Entity Framework and code first approach to connect SQL server database.
Create ASP.NET Core Web API using Visual Studio 2022
We can use Visual Studio 2022 to create an ASP.NET Core Web API with .NET 6.0.
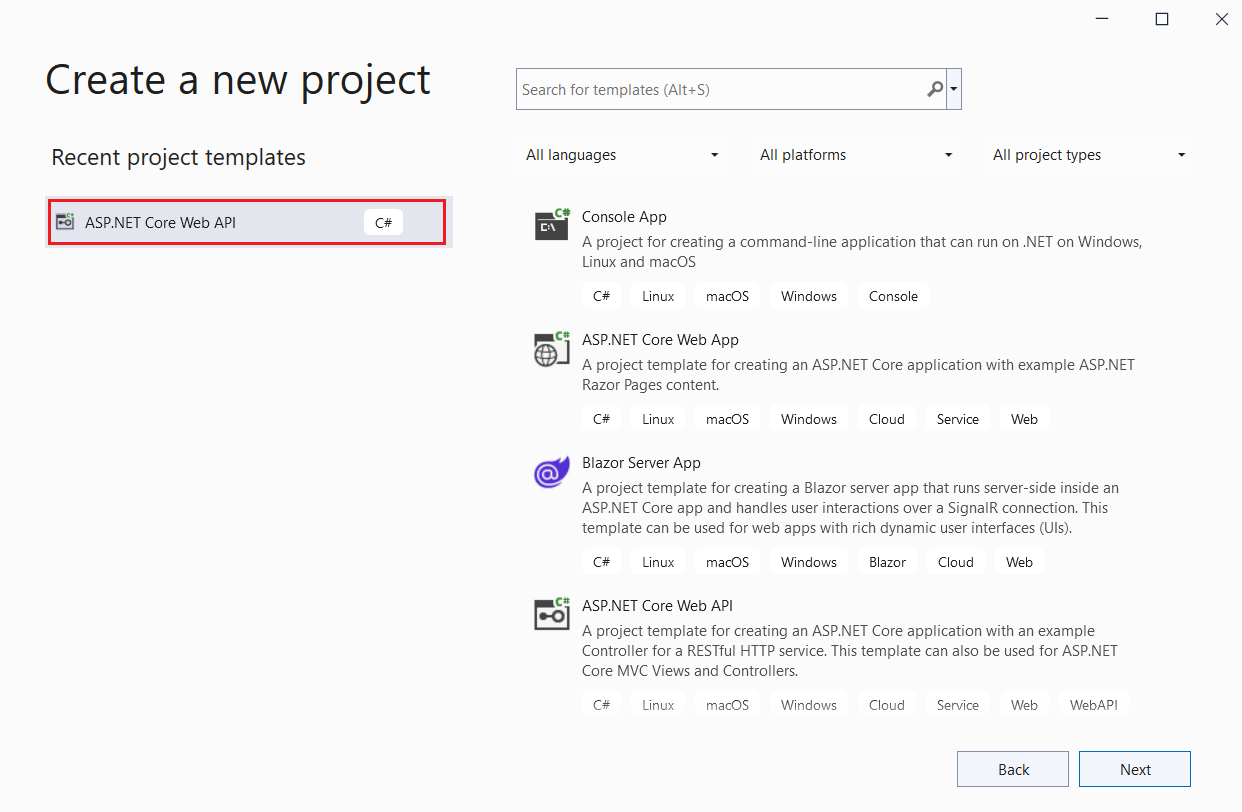
We have chosen the ASP.NET Core Web API template from Visual Studio and given a valid name to the project.
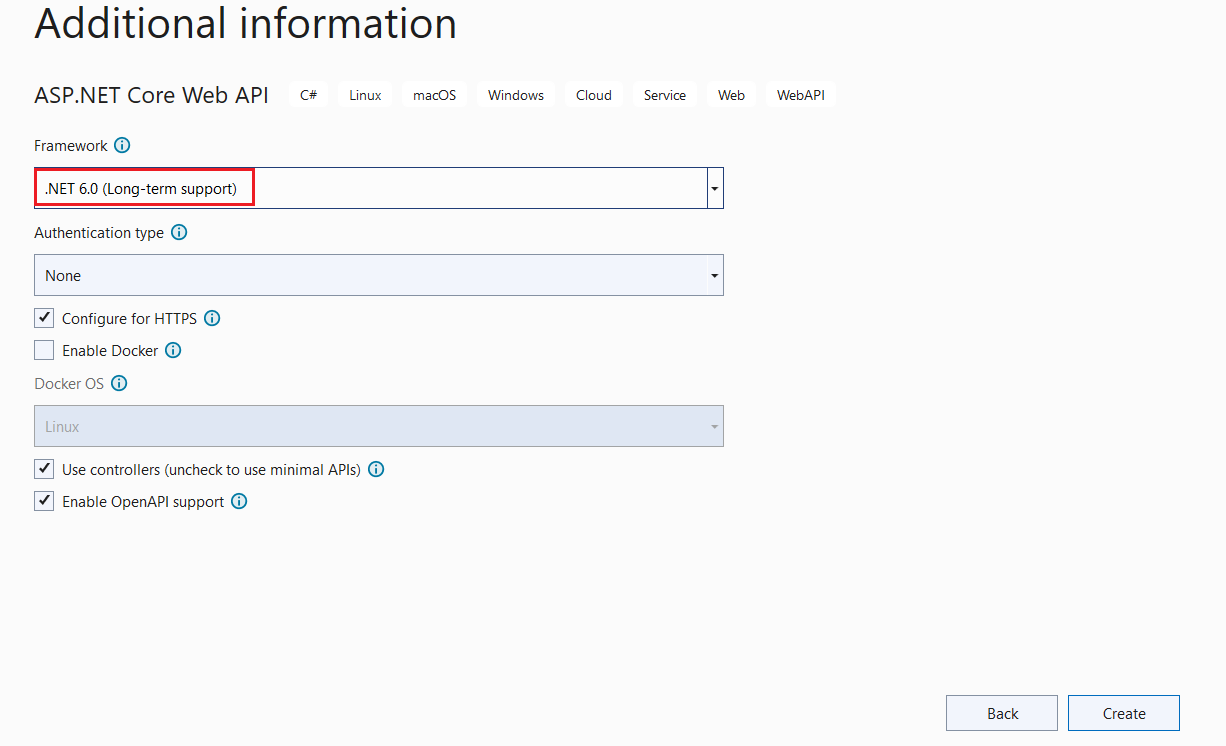
We can choose the .NET 6.0 framework. We have also chosen the default Open API support. This will create a swagger documentation for our project.
We must install the libraries below using NuGet package manger.
HtmlAgilityPack
Microsoft.EntityFrameworkCore.SqlServer
Microsoft.EntityFrameworkCore.Tools
We can add database connection string and parallel task counts inside the appsettings.
appsettings.json
{
"Logging": {
"LogLevel": {
"Default": "Information",
"Microsoft.AspNetCore": "Warning"
}
},
"AllowedHosts": "*",
"ConnectionStrings": {
"ConnStr": "Data Source=(localdb)\\MSSQLLocalDB;Initial Catalog=AnalyticsDB;Integrated Security=True;ApplicationIntent=ReadWrite;MultiSubnetFailover=False"
},
"ParallelTasksCount": 20
}
Database connection string will be used by entity framework to connect SQL database and parallel task counts will be used by web scraping parallel foreach code.
We can create a Feed class inside a Models folder. This class will be used to get required information from C# Corner RSS feeds.
Feed.cs
namespace Analyitcs.NET6._0.Models
{
public class Feed
{
public string Link { get; set; }
public string Title { get; set; }
public string FeedType { get; set; }
public string Author { get; set; }
public string Content { get; set; }
public DateTime PubDate { get; set; }
public Feed()
{
Link = "";
Title = "";
FeedType = "";
Author = "";
Content = "";
PubDate = DateTime.Today;
}
}
}
We can create an ArticleMatrix class inside the Models folder. This class will be used to get information for each article / blog once we get after web scraping.
ArticleMatrix.cs
using System.ComponentModel.DataAnnotations.Schema;
namespace Analyitcs.NET6._0.Models
{
public class ArticleMatrix
{
public int Id { get; set; }
public string? AuthorId { get; set; }
public string? Author { get; set; }
public string? Link { get; set; }
public string? Title { get; set; }
public string? Type { get; set; }
public string? Category { get; set; }
public string? Views { get; set; }
[Column(TypeName = "decimal(18,4)")]
public decimal ViewsCount { get; set; }
public int Likes { get; set; }
public DateTime PubDate { get; set; }
}
}
We can create our DB context class for Entity framework.
MyDbContext.cs
using Microsoft.EntityFrameworkCore;
namespace Analyitcs.NET6._0.Models
{
public class MyDbContext : DbContext
{
public MyDbContext(DbContextOptions<MyDbContext> options)
: base(options)
{
}
public DbSet<ArticleMatrix>? ArticleMatrices { get; set; }
protected override void OnModelCreating(ModelBuilder builder)
{
base.OnModelCreating(builder);
}
}
}
We will use this MyDbContext class later for saving data to the database.
We can create our API controller AnalyticsController and add web scraping code inside it.
AnalyticsController.cs
using Analyitcs.NET6._0.Models;
using HtmlAgilityPack;
using Microsoft.AspNetCore.Http;
using Microsoft.AspNetCore.Mvc;
using System.Globalization;
using System.Net;
using System.Xml.Linq;
namespace Analyitcs.NET6._0.Controllers
{
[Route("api/[controller]")]
[ApiController]
public class AnalyticsController : ControllerBase
{
readonly CultureInfo culture = new("en-US");
private readonly MyDbContext _dbContext;
private readonly IConfiguration _configuration;
public AnalyticsController(MyDbContext context, IConfiguration configuration)
{
_dbContext = context;
_configuration = configuration;
}
[HttpPost]
[Route("CreatePosts/{authorId}")]
public async Task<ActionResult> CreatePosts(string authorId)
{
try
{
XDocument doc = XDocument.Load("https://www.c-sharpcorner.com/members/" + authorId + "/rss");
if (doc == null)
{
return BadRequest("Invalid Author Id");
}
var entries = from item in doc.Root.Descendants().First(i => i.Name.LocalName == "channel").Elements().Where(i => i.Name.LocalName == "item")
select new Feed
{
Content = item.Elements().First(i => i.Name.LocalName == "description").Value,
Link = (item.Elements().First(i => i.Name.LocalName == "link").Value).StartsWith("/") ? "https://www.c-sharpcorner.com" + item.Elements().First(i => i.Name.LocalName == "link").Value : item.Elements().First(i => i.Name.LocalName == "link").Value,
PubDate = Convert.ToDateTime(item.Elements().First(i => i.Name.LocalName == "pubDate").Value, culture),
Title = item.Elements().First(i => i.Name.LocalName == "title").Value,
FeedType = (item.Elements().First(i => i.Name.LocalName == "link").Value).ToLowerInvariant().Contains("blog") ? "Blog" : (item.Elements().First(i => i.Name.LocalName == "link").Value).ToLowerInvariant().Contains("news") ? "News" : "Article",
Author = item.Elements().First(i => i.Name.LocalName == "author").Value
};
List<Feed> feeds = entries.OrderByDescending(o => o.PubDate).ToList();
string urlAddress = string.Empty;
List<ArticleMatrix> articleMatrices = new();
_ = int.TryParse(_configuration["ParallelTasksCount"], out int parallelTasksCount);
Parallel.ForEach(feeds, new ParallelOptions { MaxDegreeOfParallelism = parallelTasksCount }, feed =>
{
urlAddress = feed.Link;
var httpClient = new HttpClient
{
BaseAddress = new Uri(urlAddress)
};
var result = httpClient.GetAsync("").Result;
string strData = "";
if (result.StatusCode == HttpStatusCode.OK)
{
strData = result.Content.ReadAsStringAsync().Result;
HtmlDocument htmlDocument = new();
htmlDocument.LoadHtml(strData);
ArticleMatrix articleMatrix = new()
{
AuthorId = authorId,
Author = feed.Author,
Type = feed.FeedType,
Link = feed.Link,
Title = feed.Title,
PubDate = feed.PubDate
};
string category = "Uncategorized";
if (htmlDocument.GetElementbyId("ImgCategory") != null)
{
category = htmlDocument.GetElementbyId("ImgCategory").GetAttributeValue("title", "");
}
articleMatrix.Category = category;
var view = htmlDocument.DocumentNode.SelectSingleNode("//span[@id='ViewCounts']");
if (view != null)
{
articleMatrix.Views = view.InnerText;
if (articleMatrix.Views.Contains('m'))
{
articleMatrix.ViewsCount = decimal.Parse(articleMatrix.Views[0..^1]) * 1000000;
}
else if (articleMatrix.Views.Contains('k'))
{
articleMatrix.ViewsCount = decimal.Parse(articleMatrix.Views[0..^1]) * 1000;
}
else
{
_ = decimal.TryParse(articleMatrix.Views, out decimal viewCount);
articleMatrix.ViewsCount = viewCount;
}
}
else
{
articleMatrix.ViewsCount = 0;
}
var like = htmlDocument.DocumentNode.SelectSingleNode("//span[@id='LabelLikeCount']");
if (like != null)
{
_ = int.TryParse(like.InnerText, out int likes);
articleMatrix.Likes = likes;
}
articleMatrices.Add(articleMatrix);
}
});
_dbContext.ArticleMatrices.RemoveRange(_dbContext.ArticleMatrices.Where(x => x.AuthorId == authorId));
foreach (ArticleMatrix articleMatrix in articleMatrices)
{
await _dbContext.ArticleMatrices.AddAsync(articleMatrix);
}
await _dbContext.SaveChangesAsync();
return Ok(articleMatrices);
}
catch
{
return BadRequest("Invalid Author Id / Unhandled error. Please try again.");
}
}
}
}
We have created a “CreatePosts” method inside the API controller. We are passing C# Corner author id to this method and get all the author post details from RSS feeds.
XDocument doc = XDocument.Load("https://www.c-sharpcorner.com/members/" + authorId + "/rss");
if (doc == null)
{
return BadRequest("Invalid Author Id");
}
var entries = from item in doc.Root.Descendants().First(i => i.Name.LocalName == "channel").Elements().Where(i => i.Name.LocalName == "item")
select new Feed
{
Content = item.Elements().First(i => i.Name.LocalName == "description").Value,
Link = (item.Elements().First(i => i.Name.LocalName == "link").Value).StartsWith("/") ? "https://www.c-sharpcorner.com" + item.Elements().First(i => i.Name.LocalName == "link").Value : item.Elements().First(i => i.Name.LocalName == "link").Value,
PubDate = Convert.ToDateTime(item.Elements().First(i => i.Name.LocalName == "pubDate").Value, culture),
Title = item.Elements().First(i => i.Name.LocalName == "title").Value,
FeedType = (item.Elements().First(i => i.Name.LocalName == "link").Value).ToLowerInvariant().Contains("blog") ? "Blog" : (item.Elements().First(i => i.Name.LocalName == "link").Value).ToLowerInvariant().Contains("news") ? "News" : "Article",
Author = item.Elements().First(i => i.Name.LocalName == "author").Value
};
List<Feed> feeds = entries.OrderByDescending(o => o.PubDate).ToList();
After that we use a parallel foreach statement to loop entire article / blog detail and scrape the data from each post.
We will get article / blog category from below code.
string category = "Uncategorized";
if (htmlDocument.GetElementbyId("ImgCategory") != null)
{
category = htmlDocument.GetElementbyId("ImgCategory").GetAttributeValue("title", "");
}
articleMatrix.Category = category;
We will get article / blog views from the code below.
var view = htmlDocument.DocumentNode.SelectSingleNode("//span[@id='ViewCounts']");
if (view != null)
{
articleMatrix.Views = view.InnerText;
if (articleMatrix.Views.Contains('m'))
{
articleMatrix.ViewsCount = decimal.Parse(articleMatrix.Views[0..^1]) * 1000000;
}
else if (articleMatrix.Views.Contains('k'))
{
articleMatrix.ViewsCount = decimal.Parse(articleMatrix.Views[0..^1]) * 1000;
}
else
{
_ = decimal.TryParse(articleMatrix.Views, out decimal viewCount);
articleMatrix.ViewsCount = viewCount;
}
}
else
{
articleMatrix.ViewsCount = 0;
}
We will get article / blog user likes from below code.
var like = htmlDocument.DocumentNode.SelectSingleNode("//span[@id='LabelLikeCount']");
if (like != null)
{
_ = int.TryParse(like.InnerText, out int likes);
articleMatrix.Likes = likes;
}
After getting all this information from each article / blog using parallel foreach statement, we have saved entire information to database using below code.
_dbContext.ArticleMatrices.RemoveRange(_dbContext.ArticleMatrices.Where(x => x.AuthorId == authorId));
foreach (ArticleMatrix articleMatrix in articleMatrices)
{
await _dbContext.ArticleMatrices.AddAsync(articleMatrix);
}
await _dbContext.SaveChangesAsync();
We must change the Program.cs class with the code change below. So that, the Entity framework connection must be established.
We can create the SQL database and table using migration commands.
We can use the command below to create migration scripts in Package Manager Console.
PM > add-migration InititalScript
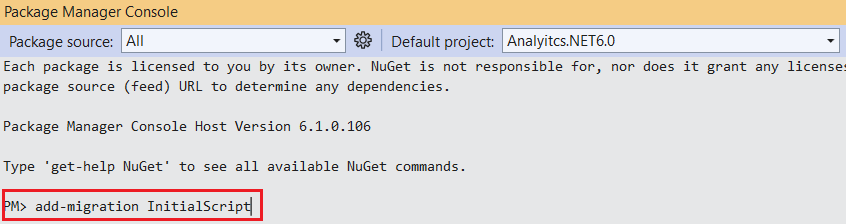
Above command will create a new migration script. We can use this script to create our database and table.
We can use the command below to update the database.
PM> update-database
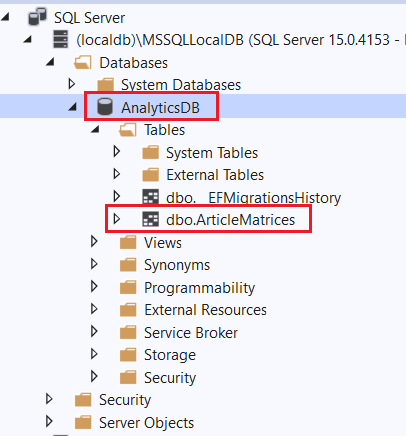
If you look at the SQL server explorer, and you can see that our new database and table is created now.
We can run our application and use swagger to execute the CreatePosts method.
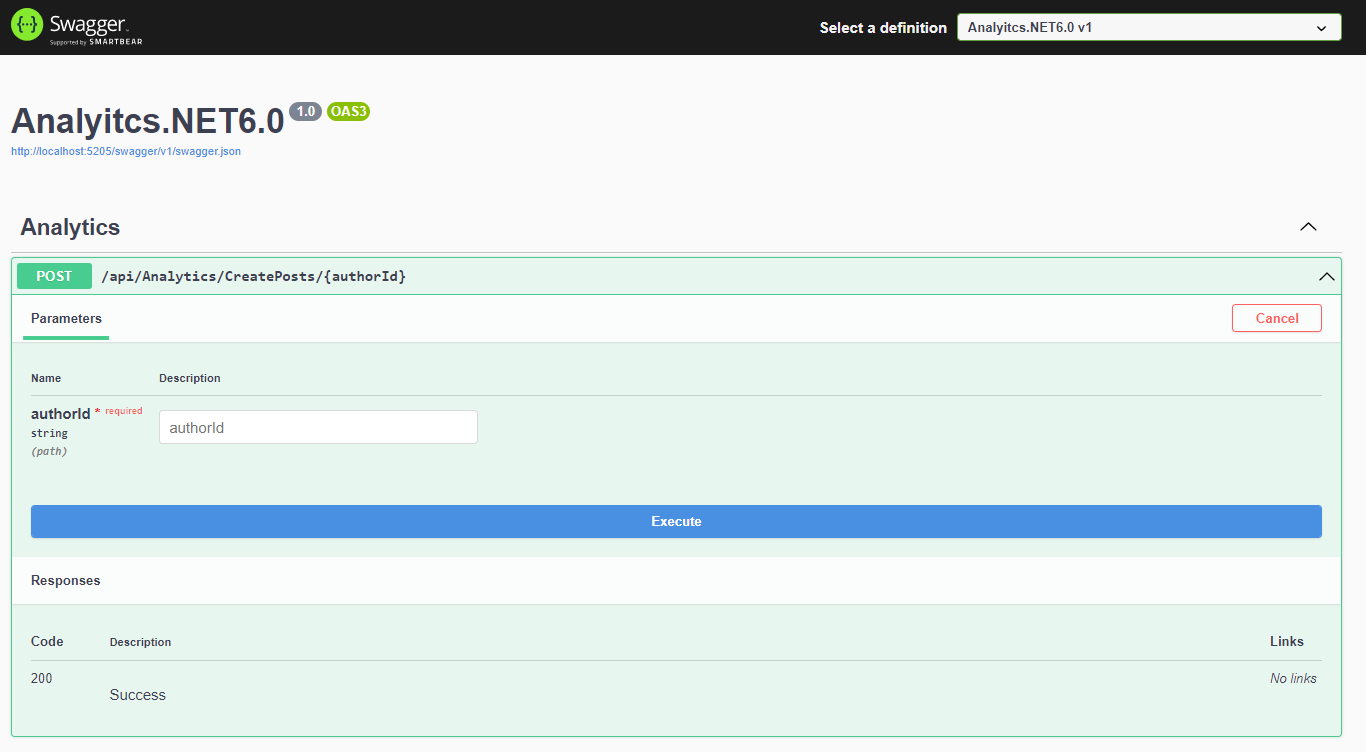
We must use our correct C# corner author id. You can easily get your author id from the profile link
Above is my profile link. sarath-lal7 is my author id.
We can use the above user id in the swagger and get all the article / blog details.
You can see that authors’ post details received in the swagger. Please note that, currently C# Corner returns maximum 100 posts details only.
If you look at the database, you can see that 100 records are available in the database as well.
If you enter the same author id again, the earlier data in the database will be removed and new data will be inserted. Hence, for a particular author a maximum of 100 records will be available on the database at any time. We can use this data to analyze the post details using any of the client-side applications like Angular or React.
I have already created a client application using Angular 8 and hosted it on Azure. You may try this Live App. I will create an Angular 13 version of this application soon.
In this post, we have seen how to scrape data from websites in .NET 6.0 application using HtmlAgilityPack library. We have used C# Corner site to scrape data from and we have scraped all the post information for a particular author using his author id. C# Corner allows us RSS feeds for each author, and we will get maximum of 100 posts for a user.
European best, cheap and reliable ASP.NET hosting with instant activation. HostForLIFE.eu is #1 Recommended Windows and ASP.NET hosting in European Continent. With 99.99% Uptime Guaranteed of Relibility, Stability and Performace. HostForLIFE.eu security team is constantly monitoring the entire network for unusual behaviour. We deliver hosting solution including Shared hosting, Cloud hosting, Reseller hosting, Dedicated Servers, and IT as Service for companies of all size.
